Overview
In the previous article,Seata's RPC Communication Source Code Analysis 01(Transport)we introduced the transmission mechanism of RPC communication. In this article, we will continue with the protocol part, completing the unaddressed encode/decode sections in the diagram.
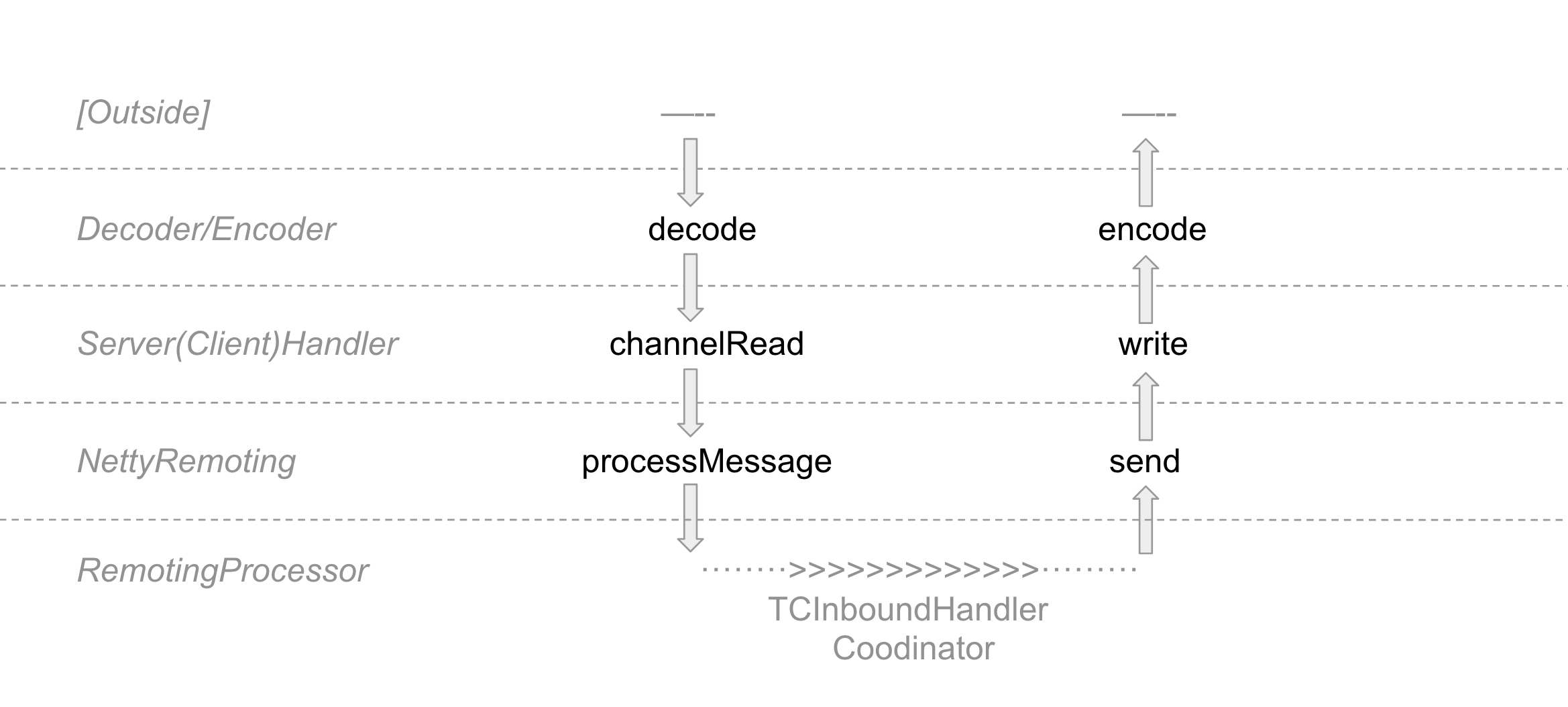
Similarly, we will delve into the topic using a question-driven approach. In this article, we aim not only to understand how binary data is parsed into the rpcMsg type but also to explore how different protocol versions are supported. So, the first question is: What does the protocol look like?
Structure of Protocol

The diagram illustrates the changes in the protocol before and after version 0.7.1 (you can also refer to the comments in ProtocolDecoderV1, and for older versions, check ProtocolV1Decoder). In the new version, the protocol consists of the following components:
- magic-code: 0xdada
- protocol-version: Version number
- full-length: Total length
- head-length: Header length
- msgtype: Message type
- serializer/codecType: Serialization method
- compress: Compression method
- requestid: Request ID
Here, we will explain the differences in protocol handling across various versions of Seata's server:
- version
<0.7.1 : Can only handle the v0 version of the protocol (the upper part of the diagram, which includes the flag section) and cannot recognize other protocol versions. - 0.7.1
<=version<2.2.0 : Can only handle the v1 version of the protocol (the lower part of the diagram) and cannot recognize other protocol versions. - version
>=2.2.0 : Can recognize and process both v0 and v1 versions of the protocol.
So, how does version 2.2.0 achieve compatibility? Let's keep that a mystery for now. Before explaining this, let's first take a look at how the v1 encoder and decoder operate. It is important to note that, just like the transmission mechanism we discussed earlier, protocol handling is also shared between the client and server. Therefore, the logic we will discuss below applies to both.
From ByteBuf to RpcMessage (What the Encoder/Decoder Does)
FirstProtocolDecoderV1
public RpcMessage decodeFrame(ByteBuf frame) {
byte b0 = frame.readByte();
byte b1 = frame.readByte();
// get version
byte version = frame.readByte();
// get header,body,...
int fullLength = frame.readInt();
short headLength = frame.readShort();
byte messageType = frame.readByte();
byte codecType = frame.readByte();
byte compressorType = frame.readByte();
int requestId = frame.readInt();
ProtocolRpcMessageV1 rpcMessage = new ProtocolRpcMessageV1();
rpcMessage.setCodec(codecType);
rpcMessage.setId(requestId);
rpcMessage.setCompressor(compressorType);
rpcMessage.setMessageType(messageType);
// header
int headMapLength = headLength - ProtocolConstants.V1_HEAD_LENGTH;
if (headMapLength > 0) {
Map<String, String> map = HeadMapSerializer.getInstance().decode(frame, headMapLength);
rpcMessage.getHeadMap().putAll(map);
}
if (messageType == ProtocolConstants.MSGTYPE_HEARTBEAT_REQUEST) {
rpcMessage.setBody(HeartbeatMessage.PING);
} else if (messageType == ProtocolConstants.MSGTYPE_HEARTBEAT_RESPONSE) {
rpcMessage.setBody(HeartbeatMessage.PONG);
} else {
int bodyLength = fullLength - headLength;
if (bodyLength > 0) {
byte[] bs = new byte[bodyLength];
frame.readBytes(bs);
// According to the previously extracted compressorType, decompression is performed as needed.
Compressor compressor = CompressorFactory.getCompressor(compressorType);
bs = compressor.decompress(bs);
SerializerType protocolType = SerializerType.getByCode(rpcMessage.getCodec());
if (this.supportDeSerializerTypes.contains(protocolType)) {
// Since this is the ProtocolDecoderV1 specifically for version 1, the serializer can directly use version1 as input.
Serializer serializer = SerializerServiceLoader.load(protocolType, ProtocolConstants.VERSION_1);
rpcMessage.setBody(serializer.deserialize(bs));
} else {
throw new IllegalArgumentException("SerializerType not match");
}
}
}
return rpcMessage.protocolMsg2RpcMsg();
}
Since the encode operation is the exact reverse of the decode operation, we won’t go over it again. Let’s continue by examining the serialize operation.
the serialize comes from SerializerServiceLoader
public static Serializer load(SerializerType type, byte version) throws EnhancedServiceNotFoundException {
// PROTOBUF
if (type == SerializerType.PROTOBUF) {
try {
ReflectionUtil.getClassByName(PROTOBUF_SERIALIZER_CLASS_NAME);
} catch (ClassNotFoundException e) {
throw new EnhancedServiceNotFoundException("'ProtobufSerializer' not found. " +
"Please manually reference 'org.apache.seata:seata-serializer-protobuf' dependency ", e);
}
}
String key = serialzerKey(type, version);
//Here is a SERIALIZER_MAP, which acts as a cache for serializer classes. The reason for caching is that the scope of SeataSerializer is set to Scope.PROTOTYPE, which prevents the class from being created multiple times.
Serializer serializer = SERIALIZER_MAP.get(key);
if (serializer == null) {
if (type == SerializerType.SEATA) {
// SPI of seata
serializer = EnhancedServiceLoader.load(Serializer.class, type.name(), new Object[]{version});
} else {
serializer = EnhancedServiceLoader.load(Serializer.class, type.name());
}
SERIALIZER_MAP.put(key, serializer);
}
return serializer;
}
public SeataSerializer(Byte version) {
if (version == ProtocolConstants.VERSION_0) {
versionSeataSerializer = SeataSerializerV0.getInstance();
} else if (version == ProtocolConstants.VERSION_1) {
versionSeataSerializer = SeataSerializerV1.getInstance();
}
if (versionSeataSerializer == null) {
throw new UnsupportedOperationException("version is not supported");
}
}
With this, the decoder obtains a Serializer. When the program reachesrpcMessage.setBody(serializer.deserialize(bs)),
let's take a look at how the deserialize method processes the data.
public <T> T deserialize(byte[] bytes) {
return deserializeByVersion(bytes, ProtocolConstants.VERSION_0);
}
private static <T> T deserializeByVersion(byte[] bytes, byte version) {
//The previous part involves validity checks, which we will skip here.
ByteBuffer byteBuffer = ByteBuffer.wrap(bytes);
short typecode = byteBuffer.getShort();
ByteBuffer in = byteBuffer.slice();
//create Codec
AbstractMessage abstractMessage = MessageCodecFactory.getMessage(typecode);
MessageSeataCodec messageCodec = MessageCodecFactory.getMessageCodec(typecode, version);
//codec decode
messageCodec.decode(abstractMessage, in);
return (T) abstractMessage;
}
This serialize does not contain much logic, the key components is in the MessageCodecFactory and Codec, let's delve deeper.
You can see that MessageCodecFactory has quite a lot of content, but in a single form, they all return message and codec according to MessageType,
so we won't show the content of factory here, we will directly look at message and codec, that is, messageCodec.decode( abstractMessage, in),
although there are still a lot of codec types, but we can see that their structure is similar, parsing each field:
// BranchRegisterRequestCodec decode
public <T> void decode(T t, ByteBuffer in) {
BranchRegisterRequest branchRegisterRequest = (BranchRegisterRequest)t;
// get xid
short xidLen = in.getShort();
if (xidLen > 0) {
byte[] bs = new byte[xidLen];
in.get(bs);
branchRegisterRequest.setXid(new String(bs, UTF8));
}
// get branchType
branchRegisterRequest.setBranchType(BranchType.get(in.get()));
short len = in.getShort();
if (len > 0) {
byte[] bs = new byte[len];
in.get(bs);
branchRegisterRequest.setResourceId(new String(bs, UTF8));
}
// get lockKey
int iLen = in.getInt();
if (iLen > 0) {
byte[] bs = new byte[iLen];
in.get(bs);
branchRegisterRequest.setLockKey(new String(bs, UTF8));
}
// get applicationData
int applicationDataLen = in.getInt();
if (applicationDataLen > 0) {
byte[] bs = new byte[applicationDataLen];
in.get(bs);
branchRegisterRequest.setApplicationData(new String(bs, UTF8));
}
}
Well, by this point, we've got the branchRegisterRequest, which can be handed off to the TCInboundHandler for processing.
But the problem is again, we only see the client (RM/TM) has the following kind of code to add encoder/decoder, that is, we know the client are using the current version of encoder/decoder processing:
bootstrap.handler(
new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new IdleStateHandler(nettyClientConfig.getChannelMaxReadIdleSeconds(),nettyClientConfig.getChannelMaxWriteIdleSeconds(),nettyClientConfig.getChannelMaxAllIdleSeconds()))
.addLast(new ProtocolDecoderV1())
.addLast(new ProtocolEncoderV1());
if (channelHandlers != null) {
addChannelPipelineLast(ch, channelHandlers);
}
}
});
But how does server handle it? And what about the promised multi-version protocol?
Multi-version protocol (version recognition and binding)
Let's start by looking at a class diagram for encoder/decoder:
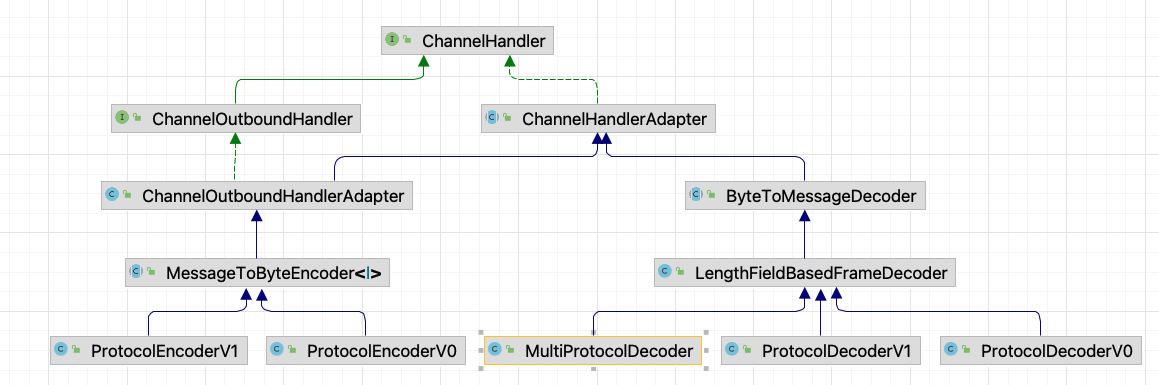
ProtocolDecoderV1 we have analyzed, ProtocolEncoderV1 is the reverse operation, it should be better understood, as for ProtocolDecoderV0 and ProtocolEncoderV0, from the diagram you can also see that they are in parallel with v1, except for the operation of v0 (although so far we haven't put him to use yet), they are both subclasses of the typical encode and decode in netty, but what about MultiProtocolDecoder? He's the protagonist of the MultiProtocolDecoder and is registered into the server's bootstrap at startup.
protected boolean isV0(ByteBuf in) {
boolean isV0 = false;
in.markReaderIndex();
byte b0 = in.readByte();
byte b1 = in.readByte();
// In fact, identifying the protocol relies on the 3rd byte (b2), as long as it is a normal new version, b2 is the version number greater than 0. For versions below 0.7, b2 is the first bit of the FLAG, which just so happens to be 0 in either case!
// v1/v2/v3 : b2 = version
// v0 : b2 = 0 ,1st byte in FLAG(2byte:0x10/0x20/0x40/0x80)
byte b2 = in.readByte();
if (ProtocolConstants.MAGIC_CODE_BYTES[0] == b0 && ProtocolConstants.MAGIC_CODE_BYTES[1] == b1 && 0 == b2) {
isV0 = true;
}
// The read bytes have to be reset back in order for each version of the decoder to parse them from scratch.
in.resetReaderIndex();
return isV0;
}
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
ByteBuf frame;
Object decoded;
byte version;
try {
// Identify the version number and get the current version number
if (isV0(in)) {
decoded = in;
version = ProtocolConstants.VERSION_0;
} else {
decoded = super.decode(ctx, in);
version = decideVersion(decoded);
}
if (decoded instanceof ByteBuf) {
frame = (ByteBuf) decoded;
ProtocolDecoder decoder = protocolDecoderMap.get(version);
ProtocolEncoder encoder = protocolEncoderMap.get(version);
try {
if (decoder == null || encoder == null) {
throw new UnsupportedOperationException("Unsupported version: " + version);
}
// First time invoke ,use a well-judged decoder for the operation
return decoder.decodeFrame(frame);
} finally {
if (version != ProtocolConstants.VERSION_0) {
frame.release();
}
// First time invoke , bind the encoder and decoder corresponding to the version, which is equivalent to binding the channel
ctx.pipeline().addLast((ChannelHandler)decoder);
ctx.pipeline().addLast((ChannelHandler)encoder);
if (channelHandlers != null) {
ctx.pipeline().addLast(channelHandlers);
}
// After binding, remove itself and do not judge it subsequently
ctx.pipeline().remove(this);
}
}
} catch (Exception exx) {
LOGGER.error("Decode frame error, cause: {}", exx.getMessage());
throw new DecodeException(exx);
}
return decoded;
}
protected byte decideVersion(Object in) {
if (in instanceof ByteBuf) {
ByteBuf frame = (ByteBuf) in;
frame.markReaderIndex();
byte b0 = frame.readByte();
byte b1 = frame.readByte();
if (ProtocolConstants.MAGIC_CODE_BYTES[0] != b0 || ProtocolConstants.MAGIC_CODE_BYTES[1] != b1) {
throw new IllegalArgumentException("Unknown magic code: " + b0 + ", " + b1);
}
byte version = frame.readByte();
frame.resetReaderIndex();
return version;
}
return -1;
}
With the above analysis, v0 finally comes in handy (when a client with an older version registers, the server assigns it a lower version of encoder/decoder), and we've figured out how multi-version protocols are recognized and bound.