Current Situation & Pain Points
For Seata, it records the before and after data of DML operations to perform possible rollback operations, and stores this data in a blob field in the database. For batch operations such as insert, update, delete, etc., the number of affected rows may be significant, concatenated into a large field inserted into the database, which may lead to the following issues:
- Exceeding the maximum write limit for a single database operation (such as the
max_allowed_packageparameter in MySQL). - Significant network IO and database disk IO overhead due to a large amount of data.
Brainstorming
For the first issue, the max_allowed_package parameter limit can be increased based on the actual situation of the business to avoid the "query is too large" problem. For the second issue, increasing bandwidth and using high-performance SSD as the database storage medium can help.
The above solutions involve external or costly measures. Is there a framework-level solution to address the pain points mentioned above?
Considering the root cause of the pain points mentioned above, the problem lies in the generation of excessively large data fields. Therefore, if the corresponding data can be compressed at the business level before data transmission and storage, theoretically, it can solve the problems mentioned above.
Feasibility Analysis
Combining the brainstorming above, in practical development, when large batch operations are required, they are often scheduled during periods of relatively low user activity and low concurrency. At such times, CPU and memory resources can be relatively more utilized to quickly complete the corresponding operations. Therefore, by consuming CPU and memory resources to compress rollback data, the size of data transmission and storage can be reduced.
At this point, two things need to be demonstrated:
- After compression, it can reduce the pressure on network IO and database disk IO. This can be measured by the total time taken for data compression + storage in the database.
- After compression, the efficiency of compression compared to the original data size. This can be measured by the data size before and after compression.
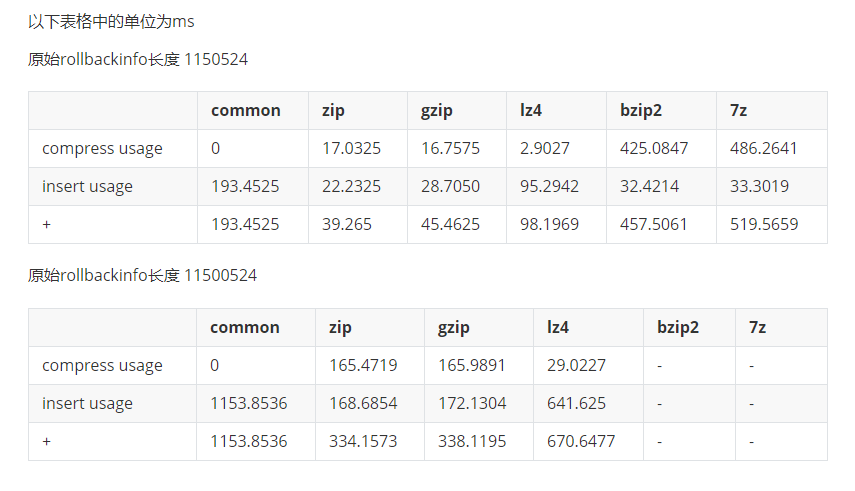
Testing the time spent on compressing network usage:
Compression Ratio Test:
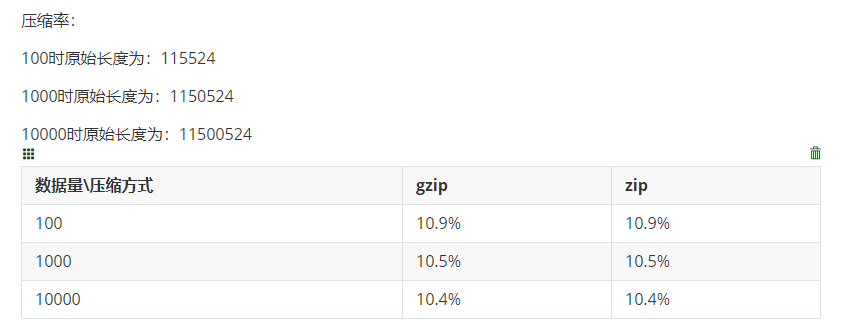
The test results clearly indicate that using gzip or zip compression can significantly reduce the pressure on the database and network transmission. At the same time, it can substantially decrease the size of the stored data.
Implementation
Implementation Approach
Partial Code
# Whether to enable undo_log compression, default is true
seata.client.undo.compress.enable=true
# Compressor type, default is zip, generally recommended to be zip
seata.client.undo.compress.type=zip
# Compression threshold for enabling compression, default is 64k
seata.client.undo.compress.threshold=64k
Determining Whether the Undo_Log Compression Feature is Enabled and if the Compression Threshold is Reached
protected boolean needCompress(byte[] undoLogContent) {
// 1. Check whether undo_log compression is enabled (1.4.2 Enabled by Default).
// 2. Check whether the compression threshold has been reached (64k by default).
// If both return requirements are met, the corresponding undoLogContent is compressed
return ROLLBACK_INFO_COMPRESS_ENABLE
&& undoLogContent.length > ROLLBACK_INFO_COMPRESS_THRESHOLD;
}
Initiating Compression for Undo_Log After Determining the Need
// If you need to compress, compress undo_log
if (needCompress(undoLogContent)) {
// Gets the compression type, default zip
compressorType = ROLLBACK_INFO_COMPRESS_TYPE;
//Get the corresponding compressor and compress it
undoLogContent = CompressorFactory.getCompressor(compressorType.getCode()).compress(undoLogContent);
}
// else does not need to compress and does not need to do anything
Save the compression type synchronously to the database for use when rolling back:
protected String buildContext(String serializer, CompressorType compressorType) {
Map<String, String> map = new HashMap<>();
map.put(UndoLogConstants.SERIALIZER_KEY, serializer);
// Save the compression type to the database
map.put(UndoLogConstants.COMPRESSOR_TYPE_KEY, compressorType.name());
return CollectionUtils.encodeMap(map);
}
Decompress the corresponding information when rolling back:
protected byte[] getRollbackInfo(ResultSet rs) throws SQLException {
// Gets a byte array of rollback information saved to the database
byte[] rollbackInfo = rs.getBytes(ClientTableColumnsName.UNDO_LOG_ROLLBACK_INFO);
// Gets the compression type
// getOrDefault uses the default value CompressorType.NONE to directly upgrade 1.4.2+ to compatible versions earlier than 1.4.2
String rollbackInfoContext = rs.getString(ClientTableColumnsName.UNDO_LOG_CONTEXT);
Map<String, String> context = CollectionUtils.decodeMap(rollbackInfoContext);
CompressorType compressorType = CompressorType.getByName(context.getOrDefault(UndoLogConstants.COMPRESSOR_TYPE_KEY,
CompressorType.NONE.name()));
// Get the corresponding compressor and uncompress it
return CompressorFactory.getCompressor(compressorType.getCode())
.decompress(rollbackInfo);
}
peroration
By compressing undo_log, Seata can further improve its performance when processing large amounts of data at the framework level. At the same time, it also provides the corresponding switch and relatively reasonable default value, which is convenient for users to use out of the box, but also convenient for users to adjust according to actual needs, so that the corresponding function is more suitable for the actual use scenario.